Powerup your Notion Safari Extension
In the previous post, we’ve discussed how to build a customized safari-to-notion Automator. It can save the page title and URL to the designated notion page in an automatic fashion. We’ve learned how to write AppleScripts, use Mac automation, and use Notion-py API to achieve this goal.
However, there are two limitations: 1) we could not save the page content in Notion, and 2) we could not process multiple pages in batch, which could significantly improve our productivity in some cases. And we are trying to solve these two challenges in this article.
Saving web contents
The AppleScript API
As you may recall, in the last post, I shared how to use the Script Editor Library to inspect the provided APIs of an Application, and the name attribute was used to fetch the title of the web page. Similarly, in this case, you may also find the text attribute for a webpage that stores the text on that web page.
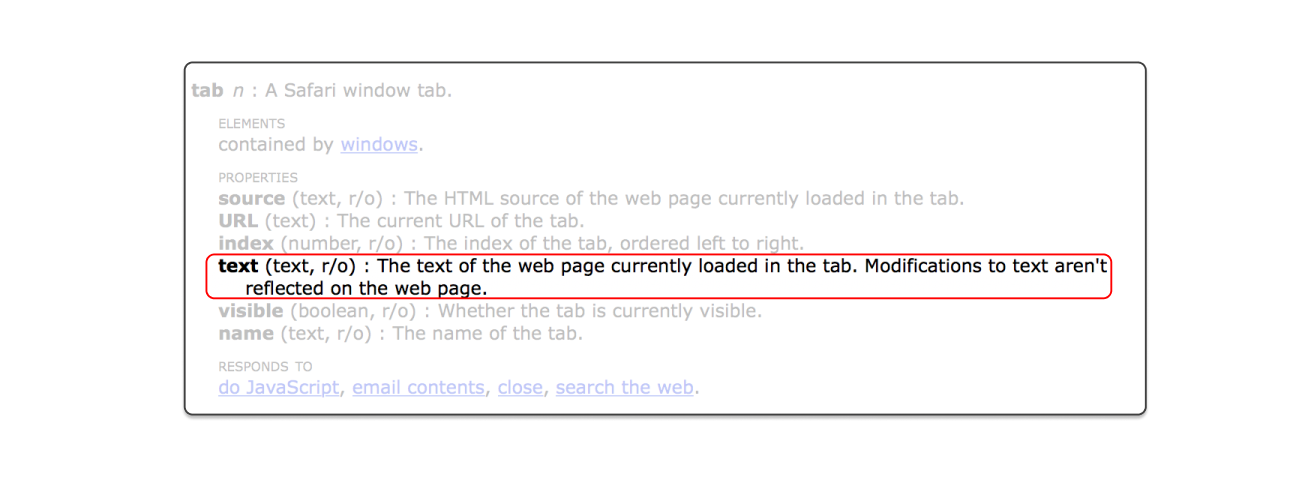
Let’s modify the AppleScript code and obtain the text value:
tell application "Safari"
set theURL to URL of current tab of window 1
set theTitle to name of current tab of window 1
set theText to text of current tab of window 1 # NEW! store the text
end tell
return {theChoice, theTitle, theURL, theText}
And you can also have access to the running results in the Run AppleScript action in Automator:

Finally, don’t forget to change our Python code as well to save the information into Notion.
from notion.client import NotionClient
import sys
from notion.block import * # NEW! import all block classes
page_selection = sys.argv[1]
tab_name = sys.argv[2]
url_string = sys.argv[3]
text_string = sys.argv[4] # NEW! save the fourth parameter as text
# ... skipped ...
row = cv.collection.add_row()
row.set_property("Name", tab_name)
row.set_property("URL", url_string)
row.children.add_new(TextBlock, title=text_string) # NEW! add the text string
You might notice the syntax for the last line is a bit different. This is because we are not setting the attribute for that row, but adding content to the associated notion pages.
The Newspaper3k API
However, the used text attribute from AppleScript will include unnecessary information like page header and footer which we don’t need. Most of the time, you only need the main text body on the website. How to achieve that?
Parsing the webpage source HTML could be a solution. However, it’s time-consuming to develop an algorithm that can robustly handle various webpages. Luckily, the Newspaper3k library in Python provides us with an elegant and neat solution. It can automatically extract the main text from the given webpage. The following exemplar code fetches the textual content in the url, and can produce a variety of meta-information:
from newspaper import Article
url = 'xx'
article = Article(url)
article.download()
article.parse()
article.text
article.top_image
article.authors
article.publish_date
It even support simple NLP analysis with the help of Natural Language Toolkit(NLTK):
article.nlp()
article.keywords
article.summary
Let’s use an exemplar article to check the actual performance. As shown in the figure below, the newspaper3k API does not only provide us with better text extraction results, but also generates some helpful meta-information that could be useful for future reference.

article = Article(url_string)
article.download(); article.parse(); article.nlp()
row.set_property("keywords", ','.join(article.keywords))
row.set_property("Summary", article.summary)
row.children.add_new(TextBlock, title=article.text)
# You can also try using the following code and compare the
# difference between
# for text in article.text.split("\n"):
# row.children.add_new(TextBlock, title=text)
Batch Processing for all tabs
To further improve productivity, you may want to save and process multiple pages in batch. Let’s try with processing all tabs in a Safari window in one click.
The for loop in AppleScript could be helpful in the scenario. In the beginning, we set up a new list called returnList to store the returned variables. The repeat with command iterates through all the tabs in the current window (window 1) and store the required data. At the end of each iteration, we append the fetched data to the returnList. And finally, we return the returnList to the python script.
# Selection part is the same
set returnList to {theChoice}
tell application "Safari"
set tabCount to number of tabs in window 1
repeat with x from 1 to tabCount
set theURL to URL of tab x of window 1
set theTitle to name of tab x of window 1
set theText to text of tab x of window 1
set returnList to returnList & {theTitle, theURL, theText}
end repeat
end tell
return returnList
In the Python script, the modification is similar. Instead of hard-coded values, we use a for loop to iterate all the passed variables:
for idx in range(1, len(sys.argv), 3):
#iterate three elements at a time
tab_name = sys.argv[idx+1]
url_string = sys.argv[idx+2]
text_string = sys.argv[idx+3]
# Processing the page
The final AppleScript and Python script
Congratulations! You’ve built a better version of the Notion Safari Extension. It’s even more powerful than the official extension in Chrome or Firefox. And I believe you can create more powerful functions with the tools I’ve shared with you.
on run {input, parameters}
set pageChoices to {"PageA", "PageB"}
set theChoice to (choose from list pageChoices with prompt "Please select the target page" default items {"PageA"}) as string
set returnList to {theChoice}
tell application "Safari"
set tabCount to number of tabs in window 1
repeat with x from 1 to tabCount
set theURL to URL of tab x of window 1
set theTitle to name of tab x of window 1
set theText to text of tab x of window 1
set returnList to returnList & {theTitle, theURL, theText}
end repeat
end tell
return returnList
end run
# safari2notion.py
from notion.client import NotionClient
import sys
from notion.block import *
from newspaper import Article
# Parsing inputs from the command line
page_selection = sys.argv[1]
page_selection_lookup_table = {
'PageA': 'https://www.notion.so/xxx',
'PageB': 'https://www.notion.so/xxx',
}
if __name__ == "__main__":
token = 'your token'
client = NotionClient(token_v2=token)
for idx in range(1, len(sys.argv), 3):
#iterate three elements at a time
tab_name = sys.argv[idx+1]
url_string = sys.argv[idx+2]
text_string = sys.argv[idx+3]
page_link = page_selection_lookup_table.get(page_selection, '')
# It is more robust if the page_selection is not a key in
# the dictionary.
article = Article(url_string)
article.download(); article.parse(); article.nlp()
if page_link != '':
cv = client.get_collection_view(page_link)
row = cv.collection.add_row()
row.set_property("Name", tab_name)
row.set_property("URL", url)
# Remember to configure your database to add the Name and URL
property
row.set_property("keywords", ','.join(article.keywords))
row.set_property("Summary", article.summary)
for text in article.text.split("\n"):
row.children.add_new(TextBlock, title=text)
Reference
Acknowledgement
Thanks to Rosen for precious advice during editing.