Projects on
Document Intelligence
Methods
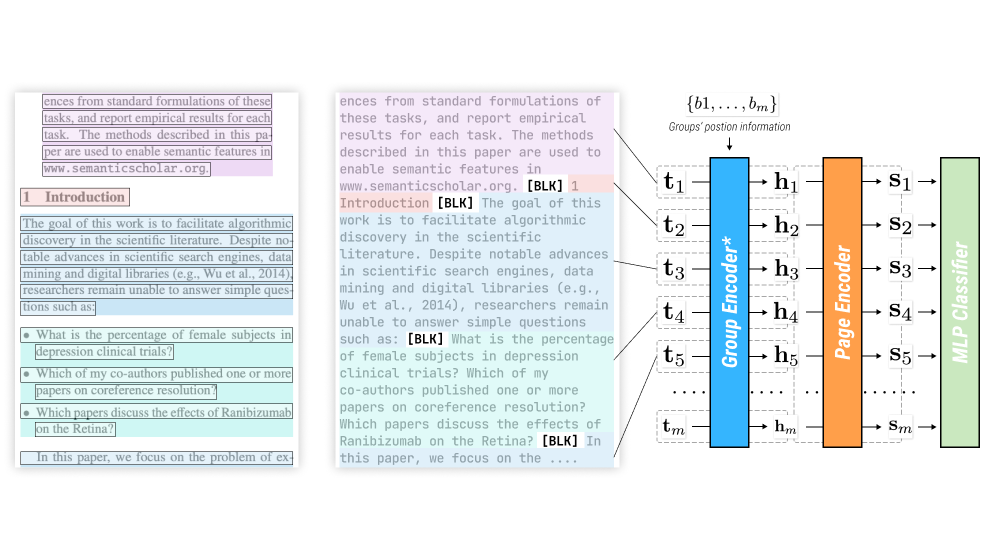
Visual Layout Structures for Scientific Text Classification
![]()
![]()
Parsing the semantic categories for texts in scientific papers is one of most important and fundamental tasks for automated information extraction and parsing for scholarly documents. Although these documents are usually intricately styled, most existing work only uses the flattened text for modeling. We propose to use visual layout structures (VILA) to improve the text classification task, and the two proposed models either bring up 1.9% accuracy improvements or 47% efficiency improvements.
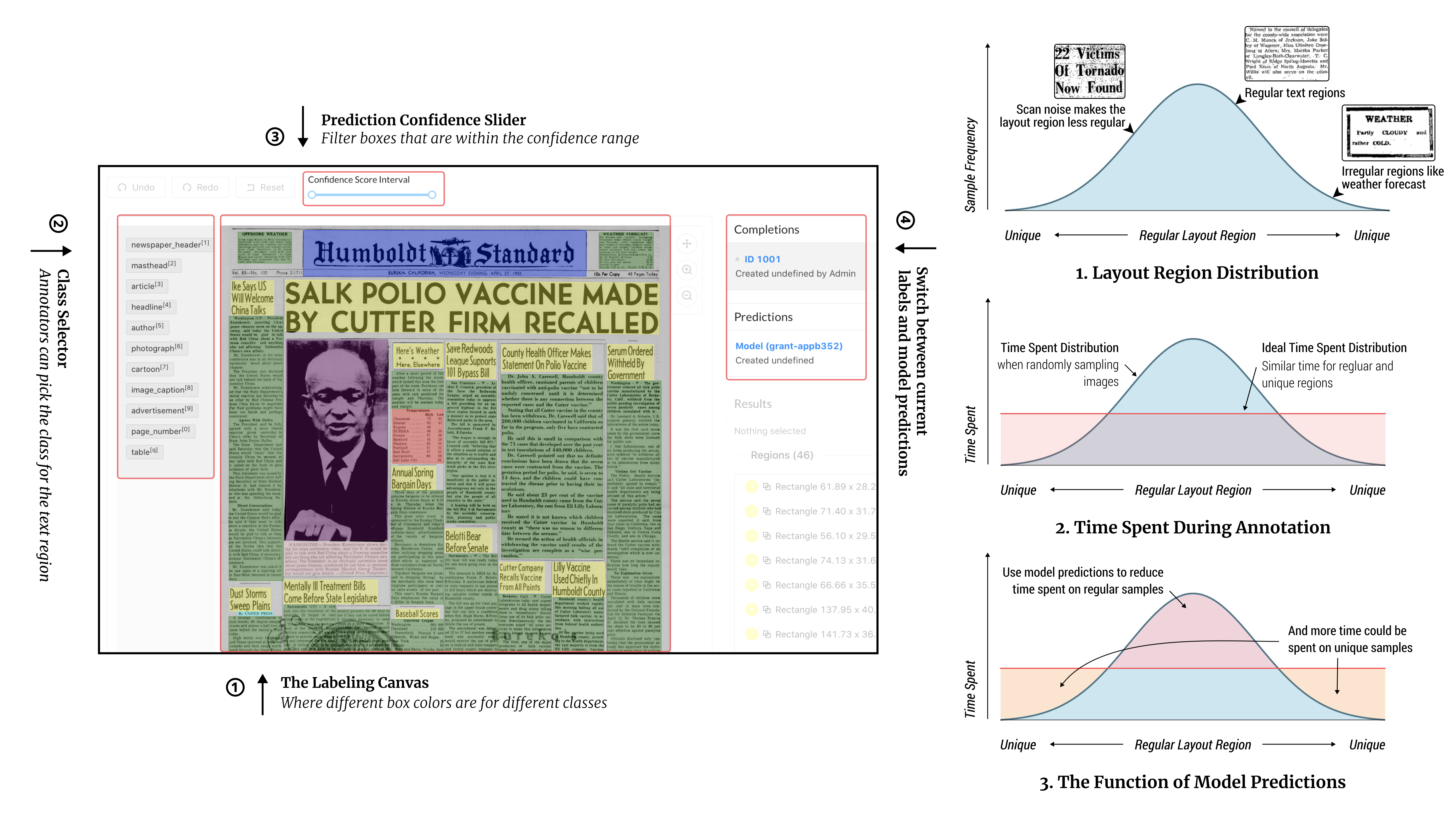
Object-Level Active Learning Based Layout Annotation
![]()
![]()
Object-Level Active Learning Based Layout Annotation, or OLALA, is a method that aims at simplifying the annotation of new layout detection datasets. It builds upon existing active learning methods, selecting only the most important object regions for labeling in practice. With the help of OLALA, we record an up-to 50% labeling efficiency improvement with less than 2% model accuracy reduction in simulation experiments.
Tools

LayoutParser
![]()
![]()

LayoutParser is a popular Python Library that aims to renovate the current document analysis with deep learning. It provides the infrastructure for both research and application for solving document-analysis related problems like layout analysis, character recognition, and many others.
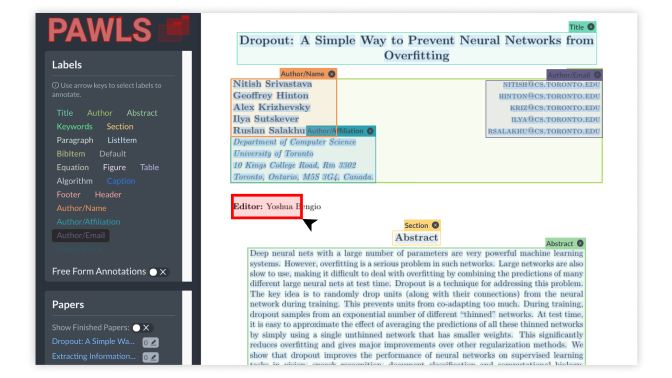
PAWLS
![]()
![]()

PAWLS is an annotation tool designed specifically for the PDF document format. It supports span-based textual annotation, N-ary relations and freeform, non-textual bounding boxes, all of which can be exported in convenient formats for training multi-modal machine learning models.
Multi-Modal Document Analysis
![]()
Multi-Modal Document Analysis (MMDA) is our latest project that helps the joint analysis of document images, layouts, and texts. It aims to bring recent advancements from NLP research together with the existing technology for document layout analysis, and produce models and pipelines with yet even better accuracy and efficiency.
PACER Docket Parser
![]()
This tool is developed for parsing the PDF-based docket files and generates a structured representation for the case information that can be used for downstream analysis with ease.
Datasets

HJDataset
![]()
![]()
HJDataset is a large dataset of Historical Japanese Documents with Complex Layouts. The inputs are document image scans and the outputs are a collection of document region bounding boxes denoting the visual layout structure and reading order of the regions. It contains over 250,000 layout element annotations of seven types.
S2-VLUE
![]()
![]()
S2-VLUE is a benchmark suite to evaluate the scientific document understanding and parsing with visual layout information. The inputs are tokens (word and their positions) parsed from PDF files and the outputs are their semantic categories. It is released along with the VILA project.